
Code and Coordinates
engineering at Geocodio
The kernel patch that almost broke our entire fleet
A new Hetzner server kept crashing every 10 minutes to 16 hours. Three suspects, one of them ruled out by a sibling server, and a trap waiting for the rest of our fleet.
By Mathias Hansen
Last week I spent three days convinced one of our newest Hetzner servers had a bad memory stick. It didn't.
It was a Linux kernel regression from a rushed security patch. It hadn't reached the rest of our fleet yet, but the next time we ran routine maintenance on any of those servers, it would have. The bug was sitting in the Debian security archive, signed and ready, waiting for us to come pull it down.
A quick clarification before we go deeper
This story is about our self-serve infrastructure, which runs on Hetzner bare-metal servers. Our enterprise tier runs on AWS with an entirely separate set of provisioning, patching, and validation processes -- and was unaffected throughout this incident.
The setup
We provisioned a new app server, app-N, on May 12. By the next morning it had gone down. Hetzner Robot showed the server as healthy and online. Tailscale showed it as unreachable. SSH didn't connect. The Hetzner status page said everything was fine.
A hard reset brought it back. Then 14 hours later, it went down again. Same pattern.
The frustrating part: out of several hundred servers in our herd, only this one was misbehaving. (We treat our servers like cattle, not pets, and the herd is usually pretty uniform.) Same hardware (a 12-core AMD Ryzen 5 3600 bare-metal box from Hetzner), same Docker stack, same workload, same Debian version. Nothing about app-N looked different from its siblings.
Once I got SSH back, I pulled the kernel logs from the previous boot.
Three suspects
I had three candidates.
Suspect 1: Beyla
The first boot I dug into pointed right at one of them:
watchdog: BUG: soft lockup - CPU#6 stuck for 48s! [beyla:5115]
watchdog: BUG: soft lockup - CPU#6 stuck for 74s! [beyla:5115]
...
watchdog: BUG: soft lockup - CPU#6 stuck for 205s! [beyla:5115]
NMI watchdog: Watchdog detected hard LOCKUP on cpu 11
igb 0000:23:00.0 enp35s0: NETDEV WATCHDOG: transmit queue 0 timed out 33100 msGrafana Beyla -- an eBPF-based auto-instrumentation tool that attaches probes to running processes for observability -- had wedged a CPU for over three minutes. Once a CPU is stuck, the kernel can't service the network card's transmit queue. The NIC's watchdog times out. The host stops responding to the network -- including Tailscale -- while the Hetzner BMC keeps seeing the hardware as alive. That explained the "online to Hetzner, offline to Tailscale" symptom perfectly.
Case closed?
Not quite. Several hundred other servers in our fleet run the exact same beyla container -- the same grafana/beyla:3.0.0 image, identical sha256, on identical hardware, with the same nginx workload underneath it. None of them have ever soft-locked. If beyla itself were the bug, that wouldn't be possible.
Verdict: Beyla wasn't the bug. It was the trigger. Something was making it lock up, but it wasn't beyla causing the lockup.
Suspect 2: Hardware fault
Before opening a Hetzner ticket, I wanted to be sure.
Two things made it plausible. First, the self-serve bare-metal boxes don't have ECC RAM -- a tradeoff we made on purpose for this tier (enterprise on AWS uses ECC throughout). The downside: a bit-flip in the wrong place causes wildly varied kernel BUGs and we have no visibility into whether they're happening. Second, the four crashes I had logs for showed four different fingerprints. Once a beyla soft lockup. Once a kernel scheduler bug in swapper/7 (the CPU idle thread -- has nothing to do with beyla). Twice, totally silent freezes where the journal cut off mid-stream with no error at all.
Different presentations of the same symptom is exactly what bad RAM looks like.
I rebooted into Hetzner's rescue system and ran:
memtester 60G 2That tests 60 GB of RAM with 18 different patterns, twice through. About two hours later it came back clean. No errors.
A clean memtester run doesn't 100% rule out hardware -- it can't catch thermal-dependent faults, time-dependent retention faults, or anything in the CPU, NIC firmware, or motherboard -- but it catches the common cases. Good enough to move on.
Verdict: Probably not hardware. Not certain, but the cheap test was clean enough to pivot.
Suspect 3: The kernel
When I started comparing app-N against its identical siblings, exactly one thing was different.
app-A: 6.1.0-44-amd64 (Debian 6.1.164-1)
app-B: 6.1.0-44-amd64 (Debian 6.1.164-1)
app-C: 6.1.0-44-amd64 (Debian 6.1.164-1)
app-N: 6.1.0-47-amd64 (Debian 6.1.170-3)The other three had been provisioned a few weeks earlier. They were running the kernel that had been current at the time. app-N, provisioned May 12, had picked up a newer kernel that had landed in the Debian security archive on May 8.
Verdict: This is our suspect.
Where the bug came from
I went looking for what changed in 6.1.170-3 and the picture clicked into place fast.
On May 7, 2026, the embargo broke on a chained pair of Linux LPE zero-days called Dirty Frag -- CVE-2026-43284 (ESP/IPsec) and CVE-2026-43500 (RxRPC). Both were actively exploited in the wild, with public exploit code available. This was about as urgent as a Linux CVE gets.
Debian shipped the fix as 6.1.170-3 (= linux-image-6.1.0-47-amd64) the very next day, May 8, via DSA-6258-1. Same-day turnaround on an emergency security release.
And the fix introduced a regression.
Upstream Linux maintainers caught it within hours. Two follow-up point releases shipped the same day -- 6.1.171 and 6.1.172, each just a single commit -- both fixing small pieces of the rushed Dirty Frag changes in the kernel's IPsec code.
Those fixes did not make it into Debian for seven more days. The patched Debian kernel -- 6.1.172-1, packaged as linux-image-6.1.0-48-amd64 -- didn't land in the security archive until May 15.
In the meantime, I spent a while digging through Debian's bug tracker and the Linux kernel mailing lists trying to find anyone else hitting the same crash signature on the same kernel. I couldn't find a clean match. That made me less confident I was looking at a real kernel regression and a bit more worried I'd been chasing the wrong thread.
What I eventually pieced together is that our specific setup was a reproducible trigger. Beyla attaches and detaches eBPF probes to running processes for observability -- and on our app servers, it does that constantly against short-lived nginx workers, many times per second. That activity hammered exactly the part of the kernel the Dirty Frag fix had broken. On most servers running this kernel, the regression sat there quietly, not really exercised by anything. On ours, the conditions to hit it lined up perfectly.
All the other servers in our fleet were fine because they were still on the old kernel. We didn't have a beyla bug. We had a kernel bug that beyla, on our specific setup, happened to be very good at triggering.
I installed 6.1.172-1 that afternoon. app-N has been stable since.
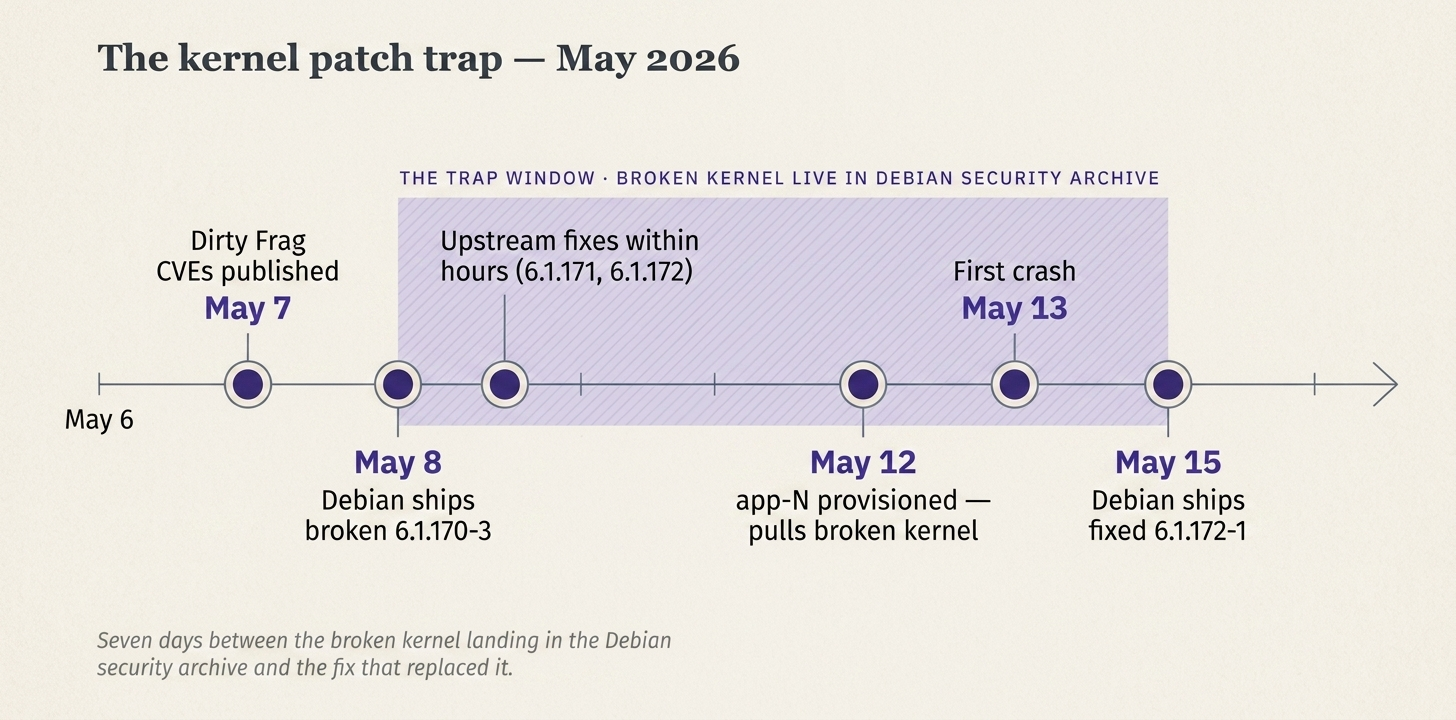
The trap window — seven days between Debian shipping the broken kernel and the fix that replaced it.
The trap
Our provisioning playbook runs apt-get upgrade against every host it touches, and reboots if the upgrade pulled in a new kernel. That's not a future-tense risk -- it's an action we run regularly, in normal business hours, treating it as routine.
None of the other servers in our fleet had picked up the broken kernel yet. We hadn't done a full provision run on any of them since the bad release shipped, so apt had never had reason to pull it down. They were still running the previous kernel, completely fine. But the bug was sitting in the Debian security archive, signed and ready. The next time we ran our provisioning playbook against any one of them, it would download the broken kernel, install it, and reboot into it. That server would then start crashing exactly the same way.
And that's not a hypothetical. We typically re-provision the fleet at least once per week as routine maintenance, which pulls down whatever's in the security archive. The broken kernel sat in that archive for seven days -- exactly the cadence we operate on. By chance, our next routine run hadn't fired yet by the time I caught the regression. If it had, every app server in our infrastructure would have come back up on the broken kernel and started crashing. In sequence. From a command we'd have run on purpose, expecting it to be safe.
We were one routine playbook run away from spreading the same crash to the next server, and a fleet-wide re-provision away from spreading it to all of them. Only app-N had stepped on the trigger because only app-N had been provisioned during the window when the broken kernel was in the archive.
Why this keeps happening
That kind of window is going to keep opening. CVE submissions are up 263% since 2020.
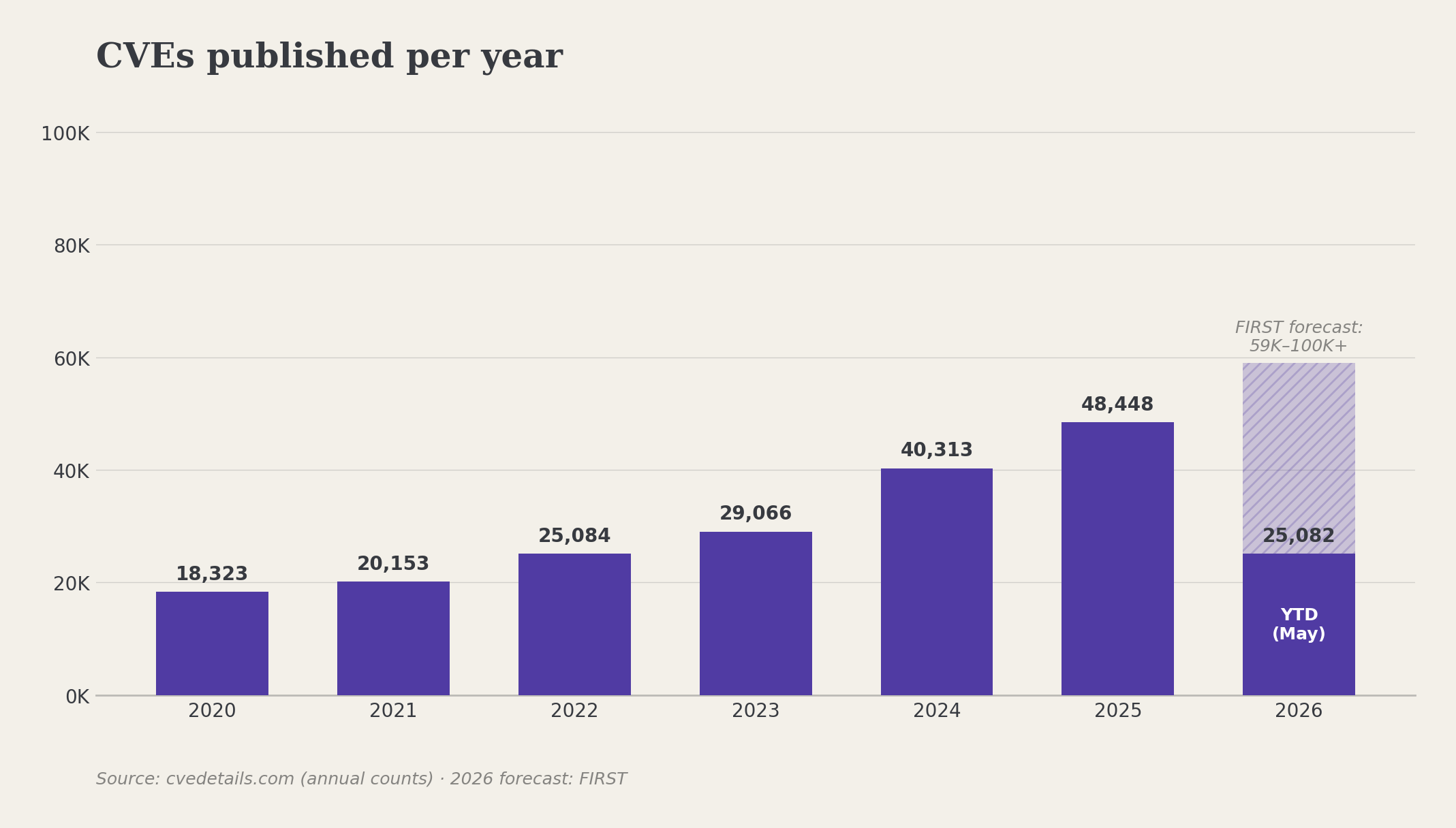
CVE publications by year, 2020 through 2026 (year-to-date). Data via cvedetails.com; 2026 forecast via FIRST.
NIST itself has stopped trying to keep up. Since April 2026 it only fully analyzes CVEs in CISA's Known Exploited Vulnerabilities catalog or federal-critical software. Everything else is officially "lowest priority."
The same week we were debugging app-N, Google announced the first confirmed AI-written zero-day exploit being used in the wild, in a mass-exploitation campaign. Not "AI will eventually do this" -- a specific exploit, in May 2026.
And that exploit isn't an outlier. AI is showing up at every layer -- vulnerability discovery, exploit development, and increasingly patch development in open-source projects that allow it. The volume of patches climbs; human review per patch drops. A Debian security update, once a thing we'd trust on sight, now deserves more suspicion than it did a year ago. Faster isn't free.
For most of my career, the default for security patches was "apply immediately, ask questions later." That default doesn't survive this anymore. The urgency a CVE gets when it's announced is generic; the urgency it deserves on your infrastructure isn't. Per CVE: how exposed are we, given our actual configuration? How mature is the available patch? A remote unauthenticated RCE with public exploit code against code we run is still worth patching in minutes -- regression risk included. A local privilege escalation on infrastructure where everyone with shell access is already trusted can wait a week.
The mistake is treating them all the same.
This cuts against one of our Development Manifesto principles -- "we use boring and known technologies." We picked Debian stable because it lags upstream and lets bugs surface before they reach us. That's right almost all the time. The exception is the emergency-CVE window, where conservatism inverts: a faster-moving distro shipping .171 and .172 the same day would have skipped right over the broken state we got stuck in.
What we shipped
We shipped two pieces the same week as the incident. One more item is still on the list.
A time-based soak gate on kernel upgrades. Before our provisioner runs apt upgrade, it now checks the publication date of the candidate linux-image-amd64 in the Debian archive. If the kernel is younger than seven days, the provisioner holds it back -- the rest of the upgrade proceeds normally, but the kernel stays on the version that's already proven itself. Seven days is sized to this exact incident: the broken kernel sat in the archive for exactly that long before Debian shipped the fix. Long enough for upstream maintainers to react to regressions like Dirty Frag; short enough that legitimate security patches still flow through within a week. When a kernel gets held back, the playbook fires one Slack notification per provisioning run rather than one per host, so the signal doesn't get buried under noise on a fleet rollout. There's an explicit bypass for emergencies, set per-run via a single environment variable that shows up in CI logs. Sometimes you do need to patch in minutes -- a remote unauthenticated RCE with public exploit code against code we run is still that case, regression risk included. The bypass keeps that path open without making it the default.
Staging as the canary, formally now. Staging has always run the same Ansible provisioner as production, but it had no enforced lead time over the fleet. We gave staging a zero-day soak window, so it pulls every new kernel immediately -- seven days before production sees it. If another Dirty-Frag-class regression lands in the security archive, staging trips first while the rest of the fleet stays on the kernel that's already proven itself. We also pinned the staging CI pipeline as an explicit full deployment, so a future edit can't quietly downgrade it into an app-only deploy and rob it of its canary role.
Per-CVE triage on the self-serve side. Still on the list. We already do this on enterprise where compliance makes it a hard requirement -- we pull from the Debian Security Tracker, cross-reference installed packages against open CVEs, and grade by severity. It needs to be made cloud-agnostic so it can run against our Hetzner hosts the same way it runs against AWS ones. Three questions before applying any patch: how exposed are we, given our actual configuration? What's the regression risk of the available fix? How long has the patch been out? "Deploy now or wait" as an explicit decision, not a reflex.
The underlying shift is the same: routine maintenance against production infrastructure now gets the same scrutiny we already give to code deployments. The soak gate is that shift made mechanical.
Wrapping up
The patch shipped the same day the embargo broke. Upstream fixed the regression within hours. Debian shipped that fix a week later. We caught it in three days because one server out of several hundred had been provisioned in the unlucky window and acted as an unplanned canary.
We caught this because we kept digging. None of it reached customers -- health checks pulled app-N out of rotation the moment it stopped responding, traffic kept flowing to the rest of the fleet, and a 30-second hard reset from Hetzner Robot brought the box back online. It would have been entirely reasonable to write the server off as a flaky new box, file a Hetzner ticket, and move on with the day. We wanted to know why. That curiosity got us to the kernel diagnosis -- and kept us from quietly rolling the same kernel out across the rest of the herd over the following week.
The herd is mooing happily again. And we've got a real canary now.
TL;DR: A rushed Debian kernel fix for an actively-exploited CVE introduced a regression that crashed our newly-provisioned server. The next routine maintenance run would have spread it to the rest of the fleet. The cost of patching too eagerly is no longer dominated by the cost of patching too slowly -- choose deliberately.
Related
The $1,000 AWS mistake
A cautionary tale about AWS VPC networking, NAT Gateways, and how a missing VPC Endpoint turned our S3 data transfers into an expensive lesson.
Geocodio's Development Manifesto
We recently wrote down the development principles we've been following at Geocodio for the past 10+ years. Thought it might be interesting to share.
How we upgraded 200 servers to Debian 13 without downtime
Rolling Debian Bookworm to Trixie across our entire fleet, one host at a time, without taking the API offline.
Get new posts in your inbox
We write about what we're working on, thinking about, and getting so excited playing around with that we accidentally stay up a bit too late.
Thanks for subscribing!